Scraping by Example - Handling JSON data
16 Jan 2015Today’s post will cover scraping sites where the pages are dynamically generated from JSON data. Compared to static pages, scraping pages rendered from JSON is often easier: simply load the JSON string and iterate through each object, extracting the relevent key/value pairs as you go.
For today’s example, I’ll demonstrate how to scrape jobs from the Brassring Applicant Tracking System (ATS). For those who’ve never encountered Brassring, their software allows companies to post job openings, collect resumes, and track applicants.
Overview
The following link takes you to the job search page for Bright Horizons, a child care company that uses the Brassring ATS to host their job openings:
https://sjobs.brassring.com/TGWebHost/home.aspx?partnerid=25595&siteid=5216
If you click the above link, you’ll land at the Welcome page. From there, click on the Search openings link.
The Search openings page presents a form where you can refine your search based on keywords, location, etc.
Once you’ve submitted your search you’ll end up at the search results page.
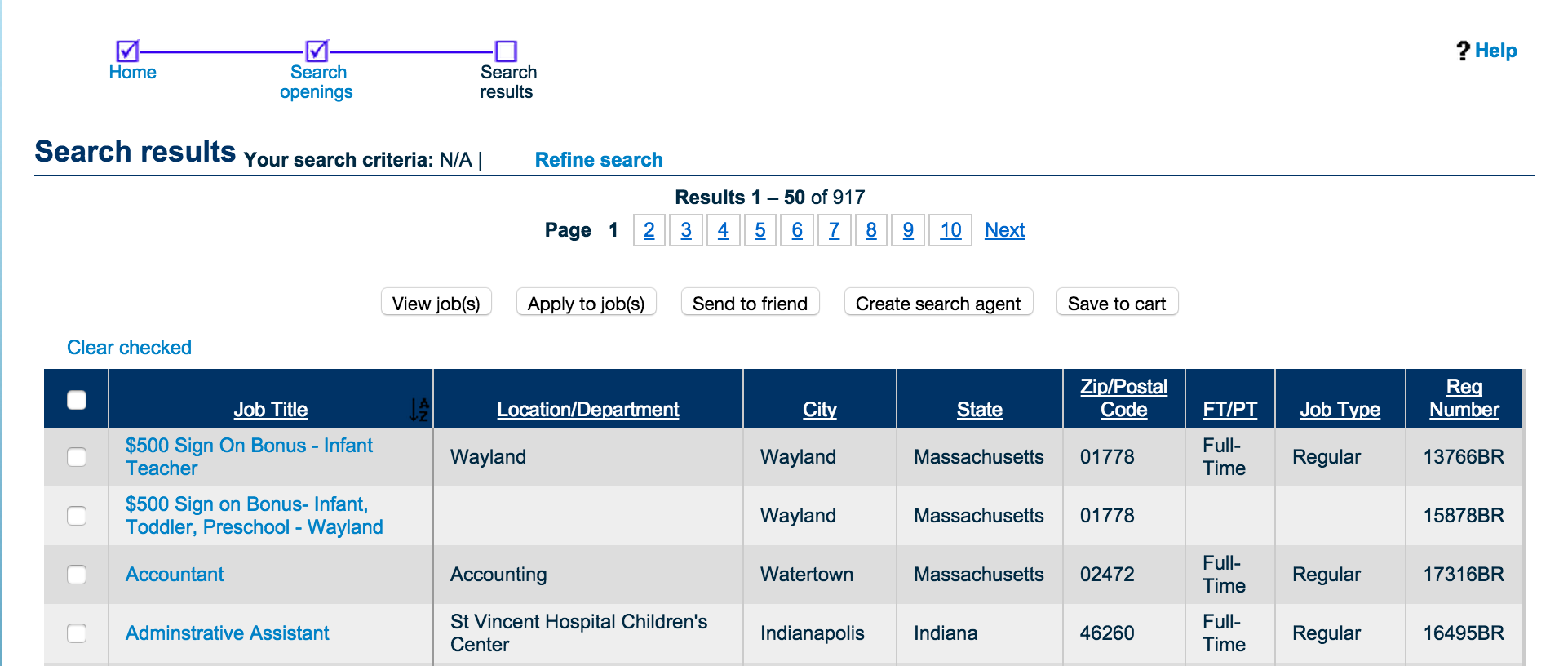
The job search results in the above table are dynamically generated from JSON data in one of the form controls.
Specifically, the jobs come from a form named frmResults with a hidden input field named ctl00$MainContent$GridFormatter$json_tabledata.
The value attribute in this field contains the jobs.
<form name="frmResults" method="post" role="main">
...
<input name="ctl00$MainContent$GridFormatter$json_tabledata"
type="hidden"
id="ctl00_MainContent_GridFormatter_json_tabledata"
class="json_tabledata"
value="<see-table-below>"
/>
</form>
Here’s the JSON data for one of the jobs shown in table form for readability.
| Key | Value |
|---|---|
| FORMTEXT12 | Milpitas |
| FORMTEXT13 | ```html </input> Child Care Lead Teacher ``` |
| FORMTEXT10 | Bright Horizons in Milpitas |
| FORMTEXT11 | 95035 |
| FORMTEXT8 | California |
| currentRowHiddenData | ```html ``` |
| AutoReq | 17611BR |
| ORMTEXT5 | Full-Time |
| FORMTEXT3 | Regular |
| chkColumn | ```html
<input type='checkbox' title='leadteacher'
id='427661' name='chkJobClientIds'
value='427661|1|480'
onClick=javascript:onCheckJob('427661',427661,'1','480','1');
/>
``` |
From the above table we can see that the job title and url are retrieved using the FORMTEXT13
key. The job’s location (city and state) is retrieved using the FORMTEXT12 and FORMTEXT8
keys.
Notice also that there’s at least ten pages of job results in the above screenshot. If want to get all of the jobs, then we’ll need to be able to handle pagination.
Let’s take stock of our requirements. In order to scrape jobs from this site we are going to have to do the following:
- Open the Welcome page
- Click on the Search openings link
- Extract the jobs from the
frmResultshidden input field - Click on the Next page link
- Repeat the previous steps until we reach the last page
Let’s get started.
Implementation
First we’ll sketch out a base class to handle scraping Brassring job sites.
import re, json
import mechanize
import urlparse
import urlutil
from bs4 import BeautifulSoup
class BrassringJobScraper(object):
def __init__(self, url):
self.br = mechanize.Browser()
self.url = url
self.soup = None
self.jobs = []
self.numJobsSeen = 0
Now, let’s add a scrape method that will encapsulate all of the logic.
def scrape(self):
self.open_search_openings_page()
self.submit_search_form()
self.scrape_jobs()
Our search openings method opens the landing page and then follows the search openings link. We use a case-insensitive regex for the link search because the case for this link varies from site to site.
def open_search_openings_page(self):
r = re.compile(r'Search openings', re.I)
self.br.open(self.url)
self.br.follow_link(self.br.find_link(text_regex=r))
Now we write the method to submit the search form. We don’t set any keywords or filter by location. We want to get all of the jobs back.
def submit_search_form(self):
self.soupify_form(soup=None, form_name='aspnetForm')
self.br.select_form('aspnetForm')
self.br.submit()
self.soup = BeautifulSoup(self.br.response().read())
Sometimes mechanize will throw the error ParseError: OPTION outside of SELECT
when you try to select a form. The call to soupify_form handles this case. It
runs the form through BeautifulSoup and sets the resulting HTML as mechanize’s
current response page:
def soupify_form(self, soup, form_name):
'''
Selecting a form with mechanize sometimes throws the error
'ParseError: OPTION outside of SELECT'
Running the form through BeautifulSoup seems to fix the issue
'''
if not soup:
soup = BeautifulSoup(self.br.response().read())
form = soup.find('form', attrs={'name': form_name})
html = str(form)
resp = mechanize.make_response(
html,
[("Content-Type", "text/html")],
self.br.geturl(),
200, "OK"
)
self.br.set_response(resp)
Now comes the meat of our scraper. We find the control containing the jobs and load in the JSON data from that control’s value.
def scrape_jobs(self):
while not self.seen_all_jobs():
t = 'ctl00_MainContent_GridFormatter_json_tabledata'
i = self.soup.find('input', id=t)
j = json.loads(i['value'])
for x in j:
# debug
print '\n'.join('%s\t%s' % (y,z) for y,z in x.items())
print '\n'
job = {}
job['title'] = self.get_title_from_job_dict(x)
job['location'] = self.get_location_from_job_dict(x)
job['url'] = self.get_url_from_job_dict(x)
self.jobs.append(job)
self.numJobsSeen += len(j)
# Next page
self.goto_next_page()
Pagination
If we look back at the screenshots in the overview, we see that the job search results
are returned 50 records at a time. In order to get all of the jobs we’ll use a method
named goto_next_page to iterate through each page and a method named seen_all_jobs
to determine once we’ve reached the last page.
If we click on the Next link from the first page and inspect the network data we see the
following POST variables sent to the server:
JobInfo:%%
recordstart:51
totalrecords:917
sortOrder:ASC
sortField:FORMTEXT13
sorting:
JobSiteInfo:
This POST data comes form a form named frmMassSelect. This form also contains the total
number of jobs in a control named totalRecords.
<form name="frmMassSelect" method="post" action="searchresults.aspx?SID=^Ma_slp_rhc_ooksXuPqc_slp_rhc__slp_rhc_4aAdjbWLwoLkE4hXrS/w7UiUsLxM6pDX4cUsEv3OAkRPQnDuWC" style="visibility:hidden" aria-hidden="true">
<input type="hidden" name="JobInfo" value="">
<input type="hidden" name="recordstart" value="1">
<input type="hidden" name="totalrecords" value="917">
<input type="hidden" name="sortOrder" value="ASC">
<input type="hidden" name="sortField" value="FORMTEXT13">
<input type="hidden" name="sorting" value="">
<input type="hidden" name="JobSiteInfo" value="">
</form>
The next page functionality works by specifying the starting record in a 50-record result
set in a control field named recordstart. In other words, recordstart is 1 and 51 for
result sets [1,50], [51,100], which correspond to pages 1 and 2 respectively.
To get each next page of results, we’ll submit the frmMassSelect form with the recordstart
control set to the number of jobs we’ve already seen plus 1.
def goto_next_page(self):
self.br.select_form('frmMassSelect')
self.br.form.set_all_readonly(False)
self.br.form['recordstart'] = '%d' % (self.numJobsSeen + 1)
self.br.submit()
self.soup = BeautifulSoup(self.br.response().read())
The seen_all_jobs method extracts the totalrecords field from the form
and determines if the number of jobs we’ve seen matches the total number of
jobs. If so, it means we’ve reached the final page of job results.
def seen_all_jobs(self):
self.soupify_form(soup=self.soup, form_name='frmMassSelect')
self.br.select_form('frmMassSelect')
return self.numJobsSeen >= int(self.br.form['totalrecords'])
Now onto to the task of extracting the jobs data. The following methods will be used to extract the title, location and jobs page url:
def get_title_from_job_dict(self, job_dict):
pass
def get_location_from_job_dict(self, job_dict):
pass
def get_soup_anchor_from_job_dict(self, job_dict):
pass
def get_url_from_job_dict(self, job_dict):
a = self.get_soup_anchor_from_job_dict(job_dict)
u = urlparse.urljoin(self.br.geturl(), a['href'])
u = self.refine_url(u)
return u
For our implementation, we’re going to leave the first three methods empty so that they can be implemented in derived classes. We do this because the keys used to extract the job title, location and url change from site to site.
Each site will have a derived class that inherits from the BrassringJobScraper base class and implements these methods according to the site’s specific key requirements.
Here’s the site-specific derived class for Bright Horizons. Note how we only have to implement three methods to scrape all of the jobs. This is because all of our logic is encapsulated in the BrassringJobScraper base class. This means we can easily add new sites that use the Brassring ATS with very little additional code.
#!/usr/bin/env python
import sys, signal
from brassring import BrassringJobScraper
from bs4 import BeautifulSoup
# BrightHorizons
URL = 'https://sjobs.brassring.com/TGWebHost/home.aspx?partnerid=25595&siteid=5216'
def sigint(signal, frame):
sys.stderr.write('Exiting...\n')
sys.exit(0)
class BrightHorizonsJobScraper(BrassringJobScraper):
def __init__(self):
super(BrightHorizonsJobScraper, self).__init__(url=URL)
def get_title_from_job_dict(self, job_dict):
t = job_dict['FORMTEXT13']
t = BeautifulSoup(t)
return t.text
def get_location_from_job_dict(self, job_dict):
l = job_dict['FORMTEXT12'] + ', ' + job_dict['FORMTEXT8']
l = l.strip()
return l
def get_soup_anchor_from_job_dict(self, job_dict):
t = job_dict['FORMTEXT13']
t = BeautifulSoup(t)
return t.a
if __name__ == '__main__':
signal.signal(signal.SIGINT, sigint)
scraper = BrightHorizonsJobScraper()
scraper.scrape()
for j in scraper.jobs:
print j
The final portion to discuss is the job url which is constructed in the get_url_from_job_dict
method.
def get_url_from_job_dict(self, job_dict):
a = self.get_soup_anchor_from_job_dict(job_dict)
u = urlparse.urljoin(self.br.geturl(), a['href'])
u = self.refine_url(u)
return u
We want the link to each job to have the following format.
https://sjobs.brassring.com/TGWebHost/jobdetails.aspx?siteid=5216&partnerid=25595&jobId=357662
But the url we extract from the JSON data has a lot of unnecessary parameters.
jobdetails.aspx?SID=%5eEnlVV9o9EpB...&jobId=357662&type=search&
JobReqLang=1&recordstart=1&JobSiteId=5216&JobSiteInfo=357662_5216&
GQId=480
The only parameter we’re interested in is jobId. We must trim the url down to our desired form.
The refine_url method filters out all other parameters except jobID and tacks on the siteid
and partnerid parameters to get our final result.
def refine_url(self, job_url):
"""
"""
items = urlutil.url_query_get(
self.url.lower(),
['partnerid', 'siteid']
)
url = urlutil.url_query_filter(job_url, 'jobId')
url = urlutil.url_query_add(url, items.iteritems())
return url
The method makes use of a helper module named urlutil that contains the code for extracting, filtering, and appending query parameters to urls.
Final Code
That’s it. Now let’s try running it.
$ ./brighthorizons.py
{'url': u'https://sjobs.brassring.com/TGWebHost/jobdetails.aspx?siteid=5216&partnerid=25595&jobId=64989', 'location': u'Racine, Wisconsin', 'title': u"Two's Teacher "}
{'url': u'https://sjobs.brassring.com/TGWebHost/jobdetails.aspx?siteid=5216&partnerid=25595&jobId=65036', 'location': u'Deerfield & Northbrook, Illinois', 'title': u"Two's Teacher "}
{'url': u'https://sjobs.brassring.com/TGWebHost/jobdetails.aspx?siteid=5216&partnerid=25595&jobId=65085', 'location': u'Ames, Iowa', 'title': u"Two's Teacher "}
{'url': u'https://sjobs.brassring.com/TGWebHost/jobdetails.aspx?siteid=5216&partnerid=25595&jobId=65113', 'location': u'Des Moines, Iowa', 'title': u"Two's Teacher "}
{'url': u'https://sjobs.brassring.com/TGWebHost/jobdetails.aspx?siteid=5216&partnerid=25595&jobId=65120', 'location': u'Iowa City, Iowa', 'title': u"Two's Teacher "}
...
If you’d like to see a working version of the code developed in this post, it’s available on github here.
Shameless Plug
Have a scraping project you’d like done? I’m available for hire. Contact me with some details about your project and I’ll give you a quote.