Scraping with CasperJS
20 Mar 2015UPDATE 09/27/2018 - The site changed after this article was originally written. I’ve updated the code that waits for the jobs to load, along with the description in this article.
In a previous post, I showed how to scrape a Javascript-heavy site by using the Selenium bindings for Python to drive a headless browser (PhantomJS). In this post, I’ll show how to scrape the same site using CasperJS.
Overview
The site being scraped is the job search page for the company L-3 Klein Associates. They use the Taleo Applicant Tracking System and the pages are almost entirely generated via Javascript:
https://l3com.taleo.net/careersection/l3_ext_us/jobsearch.ftl
Click the link and you’ll see a job listing like the following:

We’re going to scrape the job title, url, and location for the first three pages of jobs listed.
Implementation
Let’s get started with some code.
First, inspect the jobs listing and you’ll see that the jobs are listed inside a table whose id
attribute is set to jobs. That means the table can be identified with the CSS selector table#jobs.

We’ll wait for this table to be rendered before we start scraping jobs.
In the following listing, we create a Casper instance and have it open the jobs page. Then we wait for the jobs table to load by
monitoring the contents of the <span> with id currentPageInfo. Once the jobs are loaded, the text within this span will get
updated to show the total number of jobs in the results. It will be something like Job Openings 1 - 25 of 1106.
We use waitFor() to wait until the text within that span matches the pattern \d+ - \d+ of \d+. Once the table has loaded, we
call processPage(). If the table does not load before the default timeout occurs, the script exits by calling terminate().
/**
* Scrape job title, url, and location from Taleo jobs page at
* https://l3com.taleo.net/careersection/l3_ext_us/jobsearch.ftl
*
* Usage: $ casperjs scraper.js
*/
var casper = require("casper").create({
pageSettings: {
userAgent: "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:23.0) Gecko/20130404 Firefox/23.0"
}
});
var url = 'https://l3com.taleo.net/careersection/l3_ext_us/jobsearch.ftl';
var currentPage = 1;
var jobs = [];
var terminate = function() {
this.echo("Exiting..").exit();
};
casper.start(url);
/* Wait for 'Job Openings 1 - 25 of 1105' to appear within span */
casper.waitFor(function() {
return /\d+ - \d+ of \d+/.test(this.fetchText('span#currentPageInfo'));
}, processPage, terminate, 5000);
casper.run();
The processPage() function is where the bulk of our work will occur. It has three parts:
- Scrape and print the jobs in the jobs table
- Exit if we’re finished scraping
- Else, click the Next link and wait for the next page of jobs to load
We’ll go over each part in turn. But first, here’s the listing:
var processPage = function() {
// Part 1: Scrape and print the jobs in the jobs table
jobs = this.evaluate(getJobs);
require('utils').dump(jobs);
// Part 2: Exit if we're finished scraping
if (currentPage >= 3 || !this.exists("table#jobs")) {
return terminate.call(casper);
}
// Part 3: Click the Next link and wait for the next page
// of jobs to load
currentPage++;
this.thenClick("div#jobPager a#next").then(function() {
this.waitFor(function() {
return currentPage === this.evaluate(getSelectedPage);
}, processPage, terminate);
});
};
Part 1: Scrape and print the jobs in the jobs table
If we inspect the jobs table, we see that:
- Each row in the table has an
idattribute that begins with the stringjob - Job urls contains the string
jobdetail.ftl?job= - A job’s location is contained in a
spanelement in the column after the one containing the job link
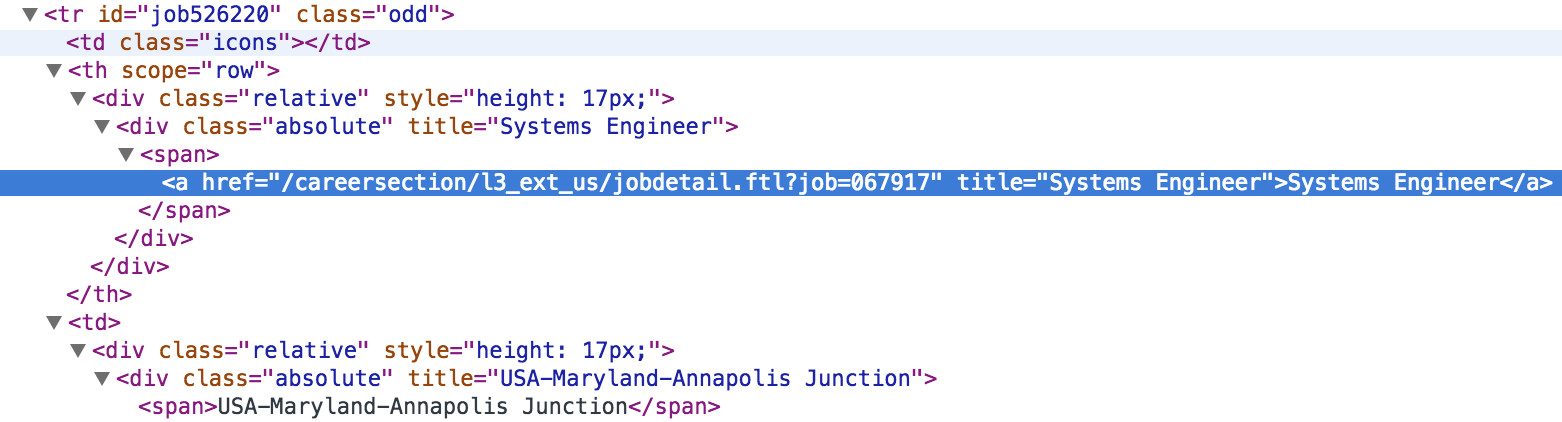
Based on the above attributes, we have all the information we need extract the title, url, and location for each job in the table.
function getJobs() {
var rows = document.querySelectorAll('table#jobs tr[id^="job"]');
var jobs = [];
for (var i = 0, row; row = rows[i]; i++) {
var a = row.cells[1].querySelector('a[href*="jobdetail.ftl?job="]');
var l = row.cells[2].querySelector('span');
var job = {};
job['title'] = a.innerText;
job['url'] = a.getAttribute('href');
job['location'] = l.innerText;
jobs.push(job);
}
return jobs;
}
Part 2: Exit if we’re finished scraping
We stop scraping once we’ve scraped three pages worth of results or we encounter a page with no jobs table, whichever comes first.
if (currentPage >= 3 || !this.exists("table#jobs")) {
return terminate.call(casper);
}
Part 3: Click the Next link and wait for the next page of jobs to load
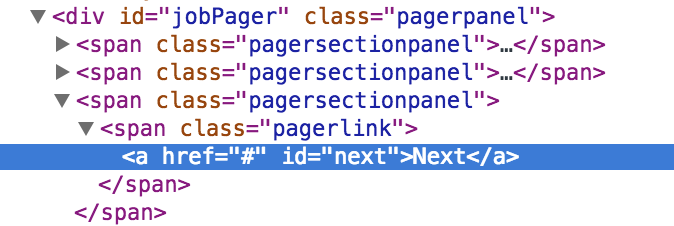
Finally, let’s look at pagination. In the pager at the bottom of the jobs listing there’s
a Next link. We’ll click on that link to get the next page of results.

If you inspect the Next link, you see it can be identified using the CSS selector div#jobPager a#next:
We’ll use Casper’s thenClick() function to click the Next link and then use waitFor() to determine
once the next page of jobs has loaded.
currentPage++;
this.thenClick("div#jobPager a#next").then(function() {
this.waitFor(function() {
return currentPage === this.evaluate(getSelectedPage);
}, processPage, terminate);
});
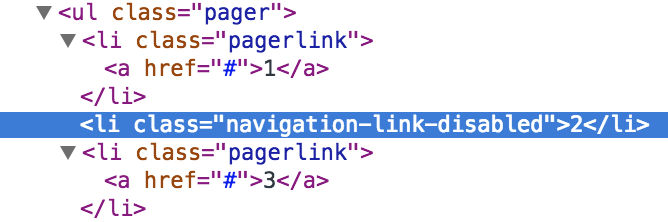
So how do know when the next page of results has loaded? Let’s go back and look at the pager again.
Note that the page we are currently on has it’s link disabled. In the image above, it’s the page 2
link. If we inspect this link, we see that it’s a list element with the CSS class navigation-link-disabled:
This means that we can write a getSelectedPage() function to find the currently selected page using the class
selector li[class="navigation-link-disabled"] and then returning that list element’s value as an integer.
// Return the current page by looking for the disabled page number link in the pager
function getSelectedPage() {
var el = document.querySelector('li[class="navigation-link-disabled"]');
return parseInt(el.textContent);
}
Now let’s put this all together: we can determine when the next page has finished loading by clicking on the
Next link and then waiting for the value returned by getSelectedPage() link to become equal to currentPage.
Hence the comparison,
return currentPage === this.evaluate(getSelectedPage);
Once these two values are the same, we can start scraping the jobs table knowing it has been updated with the next page of jobs.
Usage
Let’s try it out:
$ casperjs scraper.js
[
{
"location": "Multiple Locations",
"title": "Software Developer",
"url": "/careersection/l3_ext_us/jobdetail.ftl?job=068394"
},
{
"location": "USA-Virginia-McLean",
"title": "Frontend Developer",
"url": "/careersection/l3_ext_us/jobdetail.ftl?job=068158"
},
{
"location": "United States",
"title": "Procurement Specialist 2",
"url": "/careersection/l3_ext_us/jobdetail.ftl?job=068020"
},
...
{
"location": "Multiple Locations",
"title": "Engineer Systems",
"url": "/careersection/l3_ext_us/jobdetail.ftl?job=067875"
}
]
Exiting..
Conclusion
If you’d like to see a working implementation of the code, it’s available on github here.
For comparison purposes, the equivalent Python/Selenium implementation I developed in a previous post is available here.