Scraping ASP.NET Pages with AJAX Pagination
04 May 2015In a previous post I showed how to scrape a page that uses AJAX to return results dynamically. In that example, the results were easy to parse (XML) and the pagination scheme was straightforward (page number in the AJAX query JSON). In this post, I’ll show a more complicated example for an ASP.NET site that uses AJAX for pagination and results.
Background
The site I’ll use as an example in today’s post is the search form provided by The American Institute of Architects for finding architecture firms in the US. The form is at the following URL.
http://architectfinder.aia.org/frmSearch.aspx
I’ll show how to scrape the names and links of the architecture firms behind the form. First, we’ll use the Chrome developer tools to inspect the requests sent for the initial form submission and the requests sent to do pagination. Then, in the second section, I’ll show how to write a scraper based off of the information in the first section.
Analyzing the Form Submission
Let’s get started. Click on the above link to get to the following search form:
Next, open the Chrome developer tools so we can capture and study the requests sent when the form is submitted.
Open the Chrome developer tools by selecting View > Developer > Developer Tools
Next, select ‘Alaska’ from the state dropdown list.
Click the Search button. After a moment our two, you’ll see the area below the search form populated with the results.
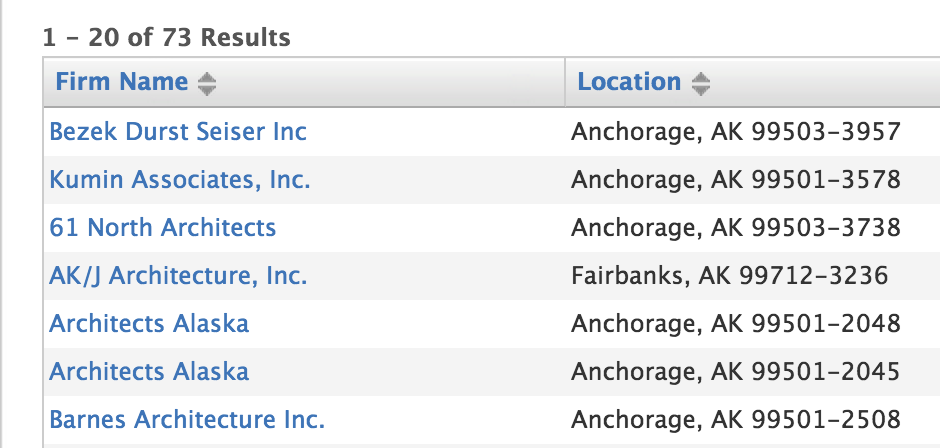
In the developer tools, click on the Network tab. You’ll see the requests that were sent when the form was submitted.
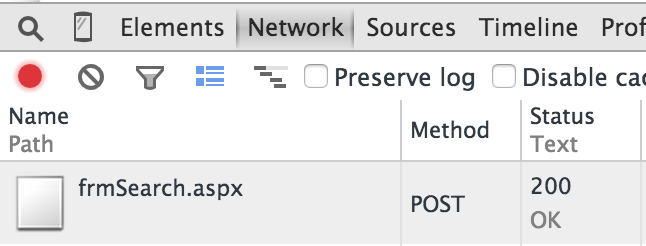
Click on the POST request to frmSearch.aspx. With the Headers tab selected, scroll down to see the Form Data that was sent with the request.
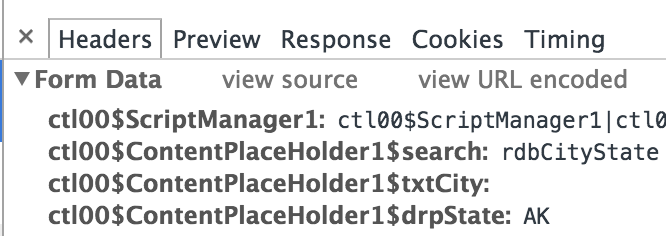
These are the variables our scraper needs to send when it submits the form. The listing below
shows the full list of variables with the __VIEWSTATE value truncated to make the whole thing
easier to read.
ctl00$ScriptManager1:ctl00$ScriptManager1|ctl00$ContentPlaceHolder1$btnSearch
__EVENTTARGET:
__EVENTARGUMENT:
__VIEWSTATE:/wEPDwUKMTU0OTkzNjEx...
ctl00$ContentPlaceHolder1$search:rdbCityState
ctl00$ContentPlaceHolder1$txtCity:
ctl00$ContentPlaceHolder1$drpState:AK
ctl00$ContentPlaceHolder1$txtZip:
ctl00$ContentPlaceHolder1$drpRadius:1
ctl00$ContentPlaceHolder1$drpBuilingType:
ctl00$ContentPlaceHolder1$drpCountry:
ctl00$ContentPlaceHolder1$dpdCandaStates:
ctl00$ContentPlaceHolder1$txtFirmname:
ctl00$ContentPlaceHolder1$hdnTabShow:0
ctl00$ContentPlaceHolder1$hdnTotalRows:
__ASYNCPOST:true
ctl00$ContentPlaceHolder1$btnSearch:Search
If you’re very observant you’ll notice that the first variable in the list ctl00$ScriptManager1
doesn’t show up in the form.
That variable gets created dynamically:
<script type="text/javascript">
//<![CDATA[
Sys.WebForms.PageRequestManager._initialize(
'ctl00$ScriptManager1',
document.getElementById('aspnetForm')
);
...
//]]>
We’ll have to create this variable and set its value manually in the scraper.
The same goes for the __ASYNCPOST:true key value pair. In that case, the variable is
created dynamically when the form is submitted:
function Sys$WebForms$PageRequestManager$_onFormSubmit(evt) {
...
formBody.append("__ASYNCPOST=true&");
}
We’ll have to create that key value pair manually too.
Now let’s take a look at the response. Click on the Response tab in the Developer Tools.

The response is a pipe-delimited string with the format
Length|Type|ID|Content
where Length is the number of bytes in Content. Once you break out the pipe-delimited string this way it becomes much easier to understand:
| Length | Type | ID | Content |
|---|---|---|---|
| 24137 | updatePanel | ctl00_ContentPlaceHolder1_pnlgrdSearchResult | <div><div style="font-weight: bold;">1 - 20 of 73 Results</div></div> … |
| 0 | hiddenField | __EVENTTARGET | |
| 0 | hiddenField | __EVENTARGUMENT | |
| 148128 | hiddenField | __VIEWSTATE | /wEPDwUKMTU0OTkzNjExNg… |
| 121 | asyncPostBackControlIDs | ctl00$ContentPlaceHolder1$btnSearch,ctl00$ContentPlaceHolder1$btnfrmSearch,ctl00$ContentPlaceHolder1$tmrLoadSearchResults | |
| 0 | postBackControlIDs | ||
| 45 | updatePanelIDs | tctl00$ContentPlaceHolder1$pnlgrdSearchResult | |
| 0 | childUpdatePanelIDs | ||
| 44 | panelsToRefreshIDs | ctl00$ContentPlaceHolder1$pnlgrdSearchResult | |
| 3 | asyncPostBackTimeout | 600 | |
| 14 | formAction | frmSearch.aspx |
Immediately we can see that the HTML results for the form submission are contained in the content for
the ctl00_ContentPlaceHolder1_pnlgrdSearchResult variable.
If you inspect the HTML of the results in your browser you’ll see that the ID matches the id attribute
of the div where the results are dynamically injected.
<div id='ctl00_ContentPlaceHolder1_pnlgrdSearchResult'>
( Here's where the HTML gets inserted from the AJAX response )
</div>
The response is basically an instruction to update div#ctl00_ContentPlaceHolder1_pnlgrdSearchResult
with the data in the Content column.
The content though is only for the first page of the results. If there are more than 20 results in all, then you have to use the pager at the bottom to click to the next page of results.
I mention this because it means we also need to pay attention to the __VIEWSTATE variable in the above
table. The contents of __VIEWSTATE will be sent when we click on page number links as you’ll see
in just a moment.
For now, let’s look at the HTML results.
<input type="hidden" name="ctl00$ContentPlaceHolder1$hdnTabShow" id="ctl00_ContentPlaceHolder1_hdnTabShow" value="0" />
<div>
<div style="font-weight: bold;">
<span id="ctl00_ContentPlaceHolder1_lblRowCountMessage">1 - 20 of 73 Results</span>
</div>
<input type="hidden" name="ctl00$ContentPlaceHolder1$hdnTotalRows" id="ctl00_ContentPlaceHolder1_hdnTotalRows" value="73" />
</div>
<div>
<table class="table_grid_b" cellspacing="0" rules="all" border="1" id="ctl00_ContentPlaceHolder1_grdSearchResult" style="border-collapse:collapse;">
<tr style="color:#555555;">
<th align="left" scope="col" style="width:30%;">
<a id="ctl00_ContentPlaceHolder1_grdSearchResult_ctl01_lnkFirmName" title="Sort" href="javascript:__doPostBack('ctl00$ContentPlaceHolder1$grdSearchResult$ctl01$lnkFirmName','')" style="text-decoration:none;">Firm Name</a>
<img src="Images/up_down.gif" style="border-width:0px;" />
</th>
<th align="left" scope="col" style="width:35%;">
<a id="ctl00_ContentPlaceHolder1_grdSearchResult_ctl01_lnkCity" title="Sort" href="javascript:__doPostBack('ctl00$ContentPlaceHolder1$grdSearchResult$ctl01$lnkCity','')" style="text-decoration:none;">Location</a>
<img src="Images/up_down.gif" style="border-width:0px;" />
</th>
<th align="left" scope="col" style="width:15%;">
<a id="ctl00_ContentPlaceHolder1_grdSearchResult_ctl01_lnkProjects" title="Sort" href="javascript:__doPostBack('ctl00$ContentPlaceHolder1$grdSearchResult$ctl01$lnkProjects','')" style="text-decoration:none;">Projects</a>
<img src="Images/down_arrow.png" style="border-width:0px;" />
</th>
</tr>
<tr class="Row1">
<td class="gridcolumn" align="left" valign="top" style="width:205px;">
<a id="ctl00_ContentPlaceHolder1_grdSearchResult_ctl02_hpFirmName" href="frmFirmDetails.aspx?FirmID=F2B34EE8-96BF-4C5E-816B-732F68F06CA5">Bezek Durst Seiser Inc</a>
</td>
<td align="left" style="width:150px;">
<span id="ctl00_ContentPlaceHolder1_grdSearchResult_ctl02_lblCity">Anchorage, AK 99503-3957</span>
</td>
<td align="left">
<a id="ctl00_ContentPlaceHolder1_grdSearchResult_ctl02_hpShowProjects" href="frmFirmDetails.aspx?FirmID=F2B34EE8-96BF-4C5E-816B-732F68F06CA5">View projects</a>
</td>
</tr>
<tr class="Row2">
<td class="gridcolumn" align="left" valign="top" style="width:205px;">
<a id="ctl00_ContentPlaceHolder1_grdSearchResult_ctl03_hpFirmName" href="frmFirmDetails.aspx?FirmID=F12ED5B3-88A1-49EC-96BC-ACFAA90C68F1">Kumin Associates, Inc.</a>
</td>
<td align="left" style="width:150px;">
<span id="ctl00_ContentPlaceHolder1_grdSearchResult_ctl03_lblCity">Anchorage, AK 99501-3578</span>
</td>
<td align="left">
<a id="ctl00_ContentPlaceHolder1_grdSearchResult_ctl03_hpShowProjects" href="frmFirmDetails.aspx?FirmID=F12ED5B3-88A1-49EC-96BC-ACFAA90C68F1">View projects</a>
</td>
</tr>
...
<tr class="footer_grid" align="right">
<td colspan="3">
<table>
<tr>
<td>
<a disabled="disabled" class="dis_class" style="display:inline-block;width:50px;"><< first</a>
<a disabled="disabled" class="dis_class" style="display:inline-block;width:50px;">< prev</a>
<a class="LinkPaging" href="javascript:__doPostBack('ctl00$ContentPlaceHolder1$grdSearchResult$ctl23$ctl02','')" style="display:inline-block;background-color:#E2E2E2;width:20px;">1</a>
<a class="LinkPaging" href="javascript:__doPostBack('ctl00$ContentPlaceHolder1$grdSearchResult$ctl23$ctl03','')" style="display:inline-block;width:20px;">2</a>
<a class="LinkPaging" href="javascript:__doPostBack('ctl00$ContentPlaceHolder1$grdSearchResult$ctl23$ctl04','')" style="display:inline-block;width:20px;">3</a>
<a class="LinkPaging" href="javascript:__doPostBack('ctl00$ContentPlaceHolder1$grdSearchResult$ctl23$ctl05','')" style="display:inline-block;width:20px;">4</a>
<a href="javascript:__doPostBack('ctl00$ContentPlaceHolder1$grdSearchResult$ctl23$ctl06','')" style="display:inline-block;width:50px;">next ></a>
<a href="javascript:__doPostBack('ctl00$ContentPlaceHolder1$grdSearchResult$ctl23$ctl07','')" style="display:inline-block;width:50px;">last >></a>
</td>
</tr>
</table>
</td>
</tr>
</table>
</div>
I’ve pulled out one of the result links so we can see the format they use:
<a id="ctl00_ContentPlaceHolder1_grdSearchResult_ctl03_hpFirmName"
href="frmFirmDetails.aspx?FirmID=F12ED5B3-88A1-49EC-96BC-ACFAA90C68F1">
Kumin Associates, Inc.
</a>
We can match the href of these links using the regex
^frmFirmDetails\.aspx\?FirmID=([A-Z0-9-]+)$
and the id attribute can be matched using the regex hpFirmName$.
Analyzing Pagination
Now let’s investigate how the pagination works for this site. Scroll down to the bottom of the results and you’ll see the pager.

Right click on the page 2 link and select Inspect Element to inspect the page 2 link in Developer Tools.
You’ll see that the HTML for each page link has the following format.
<a class="LinkPaging" href="javascript:__doPostBack('ctl00$ContentPlaceHolder1$grdSearchResult$ctl23$ctl03','')">2</a>
So when you click a page link in the pager the __doPostBack() function is called with the first argument set. Here’s
the defininition of __doPostBack:
var theForm = document.forms['aspnetForm'];
if (!theForm) {
theForm = document.aspnetForm;
}
function __doPostBack(eventTarget, eventArgument) {
if (!theForm.onsubmit || (theForm.onsubmit() != false)) {
theForm.__EVENTTARGET.value = eventTarget;
theForm.__EVENTARGUMENT.value = eventArgument;
theForm.submit();
}
}
So __doPostBack() sets the __EVENTTARGET variable to the first argument passed and submits the search form.
For our scraper that means we can extract the argument to __doPostBack() with a regex like __doPostBack\('([^']+)
and then submit the form with __EVENTTARGET set to the value of the matched substring.
Now let’s see this in action.
Click on the page 2 link so we can inspect the variables in the Network tab of the Developer Tools.
ctl00$ScriptManager1:ctl00$ContentPlaceHolder1$pnlgrdSearchResult|ctl00$ContentPlaceHolder1$grdSearchResult$ctl23$ctl03
ctl00$ContentPlaceHolder1$search:rdbCityState
ctl00$ContentPlaceHolder1$txtCity:
ctl00$ContentPlaceHolder1$drpState:AK
ctl00$ContentPlaceHolder1$txtZip:
ctl00$ContentPlaceHolder1$drpRadius:1
ctl00$ContentPlaceHolder1$drpBuilingType:
ctl00$ContentPlaceHolder1$drpCountry:
ctl00$ContentPlaceHolder1$dpdCandaStates:
ctl00$ContentPlaceHolder1$txtFirmname:
ctl00$ContentPlaceHolder1$hdnTabShow:0
ctl00$ContentPlaceHolder1$hdnTotalRows:73
__EVENTTARGET:ctl00$ContentPlaceHolder1$grdSearchResult$ctl23$ctl03
__EVENTARGUMENT:
__VIEWSTATE:/wEPDwUKMTU0OTkzNj...
__ASYNCPOST:true
:
Once again, notice that ctl00$ScriptManager1 doesn’t show up in the form but it shows up again here,
this time with the value
ctl00$ContentPlaceHolder1$pnlgrdSearchResult|ctl00$ContentPlaceHolder1$grdSearchResult$ctl23$ctl03
As before, we’ll have to create this key value pair in the scraper to make the pagination request work.
You can see that the __EVENTTARGET variable is set to the value of the argument passed to __doPostBack()
in the page 2 link.
There’s also a control key value that’s no longer in the listing if you compare this listing to the one
ealier from the form submission, btnSearch:Search. That’s the control for the Search input control. It
doesn’t get sent for pagination.
There’s one more point we need to take note of.
The __VIEWSTATE variable is set to the same value we got back from the server when it sent the first
page of results. We need to use the __VIEWSTATE value the server provides us to get the pagination to
work.
Let’s take stock of what we need our scraper to do to get all of the results for a given state:
- Select the aspnetForm form
- Select a state
- Create and set the necessary request variables not present in form (
ASYNCPOSTandctl00$ScriptManager1) - Submit the form
- Extract the results from the
pnlgrdSearchResultvariable - Extract the
__VIEWSTATE - Extract
__EVENTTARGETargument from the next page link - Submit the form again with our new variables
- Repeat until we get to the last page of results
Implementation
At this point we’ve got enough information about how the site works to write our scraper.
Here’s the code we’ll start out with. As we go along, we’ll add the code to implement the scraping logic we discussed in the first part of this post.
#!/usr/bin/env python
"""
Python script for scraping the results from http://architectfinder.aia.org/frmSearch.aspx
"""
__author__ = 'Todd Hayton'
import re
import urlparse
import mechanize
from bs4 import BeautifulSoup
class ArchitectFinderScraper(object):
def __init__(self):
self.url = "http://architectfinder.aia.org/frmSearch.aspx"
self.br = mechanize.Browser()
self.br.addheaders = [('User-agent',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.63 Safari/535.7')]
if __name__ == '__main__':
scraper = ArchitectFinderScraper()
scraper.scrape()
The bulk of our scraping work will be done in a method named scrape_state_firms() that will
scrape all of the results for a given state, handling pagination in the process.
Submitting the Form
First, I’ll go over selecting and submitting the form. If you inspect the HTML of the search form
you’ll see that its name attribute is set to aspnetForm.
<form name="aspnetForm" method="post" action="frmSearch.aspx" onsubmit="javascript:return WebForm_OnSubmit();" id="aspnetForm">
We’‘ll pass that as the argument to mechanize’s select_form() method.
def scrape_state_firms(self, state_item):
'''
Scrape all of the firm listed for a given state
'''
self.br.open(self.url)
s = BeautifulSoup(self.br.response().read())
saved_form = s.find('form', id='aspnetForm').prettify()
self.br.select_form('aspnetForm')
self.br.form['ctl00$ContentPlaceHolder1$drpState'] = [ state_item.name ]
Note that I save a copy of the form’s HTML. That’s so that later, when we do the pagination, we still have a copy of the form to work with when we update the variables to get the next page of results.
Now let’s print out the controls that mechanize has picked up so far from selecting the form.
(Pdb) print '\n'.join(['%s:%s (%s)' % (c.name,c.value,c.disabled) for c in self.br.form.controls])
Note that I also print out whether or not a control is disabled. It shows up as True or False in parentheses.
Our print statement shows the following control key value pairs:
__EVENTTARGET: (False)
__EVENTARGUMENT: (False)
__VIEWSTATE:/wEPDwUKMTU0OTkzNjExN...
ctl00$ContentPlaceHolder1$btnAccept:Ok (False)
None:None (False)
ctl00$ContentPlaceHolder1$search:['rdbCityState'] (False)
ctl00$ContentPlaceHolder1$txtCity: (False)
ctl00$ContentPlaceHolder1$drpState:['AK'] (False)
ctl00$ContentPlaceHolder1$txtZip: (False)
ctl00$ContentPlaceHolder1$drpRadius:['1'] (False)
ctl00$ContentPlaceHolder1$drpBuilingType:[''] (False)
ctl00$ContentPlaceHolder1$drpCountry:[''] (False)
ctl00$ContentPlaceHolder1$dpdCandaStates:[''] (False)
ctl00$ContentPlaceHolder1$btnSearch:Search (True)
ctl00$ContentPlaceHolder1$txtFirmname: (False)
ctl00$ContentPlaceHolder1$btnfrmSearch:Search (True)
ctl00$ContentPlaceHolder1$hdnTabShow:0 (False)
ctl00$ContentPlaceHolder1$hdnTotalRows: (False)
None:None (False)
Note that two of the controls, btnfrmSearch and btnAccept didn’t show up in the
Developer Tools variable list earlier in this post.
The first control, btnfrmSearch, is used for searching for a firm by name. The second control,
btnAccept, is the Accept button a user clicks on to accept the site’s Terms of Use (you probably
saw this the first time you visited the site). We’ll remove both of these controls before
submitting the form.
Also, if you examine the btnSearch control you’ll see that it’s currently disabled. We’ll need
to enable it before we submit the form.
Let’s do all that and also create controls for __ASYNCPOST and ctl00$ScriptManager1 as discussed
earlier in this post.
def scrape_state_firms(self, state_item):
...
self.br.form.new_control('hidden', '__ASYNCPOST', {'value': 'true'})
self.br.form.new_control('hidden', 'ctl00$ScriptManager1', {'value': 'ctl00$ScriptManager1|ctl00$ContentPlaceHolder1$btnSearch'})
self.br.form.fixup()
ctl = self.br.form.find_control('ctl00$ContentPlaceHolder1$btnfrmSearch')
self.br.form.controls.remove(ctl)
ctl = self.br.form.find_control('ctl00$ContentPlaceHolder1$btnAccept')
self.br.form.controls.remove(ctl)
ctl = self.br.form.find_control('ctl00$ContentPlaceHolder1$btnSearch')
ctl.disabled = False
self.br.submit()
Now that we’ve submitted the form, let’s see how to extract and print out the names and links of the architecture firms from the results sent back in the AJAX response.
def scrape_state_firms(self, state_item):
...
pageno = 2
while True:
resp = self.br.response().read()
it = iter(resp.split('|'))
kv = dict(zip(it, it))
s = BeautifulSoup(kv['ctl00_ContentPlaceHolder1_pnlgrdSearchResult'])
r1 = re.compile(r'^frmFirmDetails\.aspx\?FirmID=([A-Z0-9-]+)$')
r2 = re.compile(r'hpFirmName$')
x = {'href': r1, 'id': r2}
for a in s.findAll('a', attrs=x):
print 'firm name: ', a.text
print 'firm url: ', urlparse.urljoin(self.br.geturl(), a['href'])
print
# Find next page number link
a = s.find('a', text='%d' % pageno)
if not a:
break
pageno += 1
I create a dictionary of key value pairs out of the AJAX response the server sends. Even though
the response is actually a string of Length|Type|ID|Content four-tuples, treating it as a string
of key value pairs separated by | works and let’s us use an ID as a key to get to its associated
Content.
This code snippet also contains the set up for the pagination (pageno = 2) which I’ll go over next.
Pagination
For the pagination, we recreate the form from the HTML we copied ealier. Then we extract the value
we need for the next page __EVENTTARGET from the next page number link. We update the form
control values again, create the variables that aren’t picked up from the form (__ASYNCPOST and
ctl100ScriptManager) and set their values to match what we saw in the Developer Tools earlier.
Then we submit the form again and repeat the whole process until we reach the last page of the results.
def scrape_state_firms(self, state_item):
...
pageno = 2
while True:
resp = self.br.response().read()
it = iter(resp.split('|'))
kv = dict(zip(it, it))
...
# Find next page number link
a = s.find('a', text='%d' % pageno)
if not a:
break
pageno += 1
# New __VIEWSTATE value
view_state = kv['__VIEWSTATE']
# Extract new __EVENTTARGET value from next page link
r = re.compile(r"__doPostBack\('([^']+)")
m = re.search(r, a['href'])
event_target = m.group(1)
# Regenerate form for next page
html = saved_form.encode('utf8')
resp = mechanize.make_response(html, [("Content-Type", "text/html")],
self.br.geturl(), 200, "OK")
self.br.set_response(resp)
self.br.select_form('aspnetForm')
self.br.form.set_all_readonly(False)
self.br.form['__EVENTTARGET'] = event_target
self.br.form['__VIEWSTATE'] = view_state
self.br.form['ctl00$ContentPlaceHolder1$drpState'] = [ state_item.name ]
self.br.form.new_control('hidden', '__ASYNCPOST', {'value': 'true'})
self.br.form.new_control('hidden', 'ctl00$ScriptManager1', {'value': 'ctl00$ContentPlaceHolder1$pnlgrdSearchResult|'+event_target})
self.br.form.fixup()
ctl = self.br.form.find_control('ctl00$ContentPlaceHolder1$btnfrmSearch')
self.br.form.controls.remove(ctl)
ctl = self.br.form.find_control('ctl00$ContentPlaceHolder1$btnAccept')
self.br.form.controls.remove(ctl)
ctl = self.br.form.find_control('ctl00$ContentPlaceHolder1$btnSearch')
self.br.form.controls.remove(ctl)
self.br.submit()
Now let’s create a method to get the list of items from the State selection drop down menu.
We’ll pass each of these items in turn to the scrape_state_firms() method we just went over:
def get_state_items(self):
self.br.open(self.url)
self.br.select_form('aspnetForm')
items = self.br.form.find_control('ctl00$ContentPlaceHolder1$drpState').get_items()
return items
Finally, let’s write a method to drive the whole scraping process by calling the methods we’ve developed so far:
def scrape(self):
'''
First we get a list of the states listed in the form select option
ctl00$ContentPlaceHolder1$drpState
Then we iterate through each state and submit the form for that state.
For each state form submission we scrape all of the results via
scrape_state_firms() handling pagination in the process.
'''
state_items = self.get_state_items()
for state_item in state_items:
if len(state_item.name) < 1:
continue
print 'Scraping firms for %s' % state_item.attrs['label']
self.scrape_state_firms(state_item)
That’s it! If you’d like to see the full implementation that you can experiment with yourself, the source code for this article is available on github.
Shameless Plug
Have a scraping project you’d like done? I’m available for hire. Contact me for a free quote.