Scraping with Puppeteer
01 Aug 2018In this post I’ll guide you through web scraping with Puppeteer, a Node library used to control Chrome (or Chromium) via the DevTools Protocol. I’ll also cover how to use Node’s built-in debugger so that you can step through the code to see how it works.
Dependencies
In order to run Puppeteer, you’ll first need to install Node if it’s not already on your system. Since the code in this article uses async/await, you’ll need Node v7.6.0 or higher.
Setup
To get started, first create a new directory for the scraper. Inside the new directory, run npm init followed by
npm install puppeteer --save.
$ mkdir scraper/
$ cd scraper/
$ npm init -y
$ npm install puppeteer --save
When you install Puppeteer in the last step, it will download a version of Chromium for you that is guaranteed to work with the API.
Background
The site I’ll use for this article is the ASPX search form at:
https://myaccount.rid.org/Public/Search/Member.aspx
Here’s a screenshot of the form:
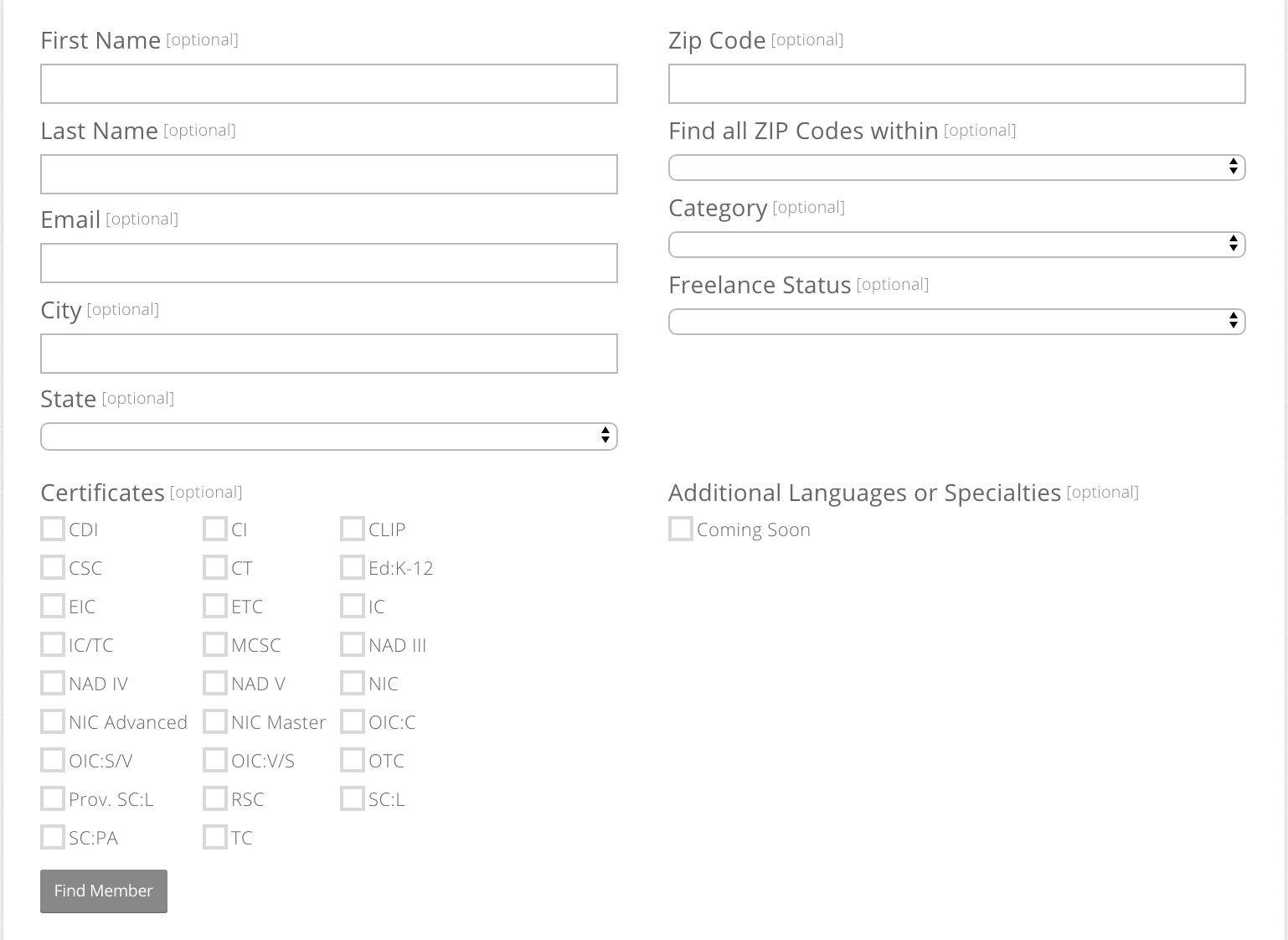
If you click Find Member without filling in any of the fields, you’ll get the following warning:

In our code we’ll fill out the State and Freelance Status fields. Specifically, we’ll iterate through all of the states in
the State field and specify Yes for the Freelance Status field. This will give us a chance to see how to handle select
dropdowns, pagination, and dynamically loaded data.
Debugger
Let’s get started. Open up your editor and enter the following code. Save it into a file named rid_scraper.js.
const puppeteer = require('puppeteer');
const url = 'https://myaccount.rid.org/Public/Search/Member.aspx';
async function main() {
const browser = await puppeteer.launch({ headless: false, slowMo: 250 });
const page = await browser.newPage();
await page.goto(url);
console.log(await page.title());
await browser.close();
}
main();
Next, let’s step through it in the command line debugger as that more accurately reflects the development process you’ll go through when writing a scraper:
$ node inspect rid_scraper.js
< Debugger listening on ws://127.0.0.1:9229/71ad933d-21d8-46d6-a8b9-2bf2c145f77c
< For help see https://nodejs.org/en/docs/inspector
< Debugger attached.
Break on start in rid_scraper.js:1
> 1 (function (exports, require, module, __filename, __dirname) { const puppeteer = require('puppeteer');
2 const url = 'https://myaccount.rid.org/Public/Search/Member.aspx';
3
Once the debugger is running, use list() to see the code. The > symbol indicates the next line you
are about to execute.
debug> list()
> 1 (function (exports, require, module, __filename, __dirname) { const puppeteer = require('puppeteer');
2 const url = 'https://myaccount.rid.org/Public/Search/Member.aspx';
3
4 async function main() {
5 const browser = await puppeteer.launch({ headless: false, slowMo: 250 });
6 const page = await browser.newPage();
Type in help to see the available commands.
debug> help
run, restart, r Run the application or reconnect
kill Kill a running application or disconnect
cont, c Resume execution
next, n Continue to next line in current file
step, s Step into, potentially entering a function
out, o Step out, leaving the current function
backtrace, bt Print the current backtrace
list Print the source around the current line where execution
is currently paused
setBreakpoint, sb Set a breakpoint
clearBreakpoint, cb Clear a breakpoint
breakpoints List all known breakpoints
breakOnException Pause execution whenever an exception is thrown
...
Next, set a breakpoint on line 5 using the set breakpoint command sb(5):
debug> sb(5)
1 (function (exports, require, module, __filename, __dirname) { const puppeteer = require('puppeteer');
2 const url = 'https://myaccount.rid.org/Public/Search/Member.aspx';
3
4 async function main() {
> 5 const browser = await puppeteer.launch({ headless: false, slowMo: 250 });
6 const page = await browser.newPage();
7
8 await page.goto(url);
9 console.log(await page.title());
10 await browser.close();
Type list again you’ll notice that there’s now a * symbol on line 5. The debugger is giving us a
visual indicator that there’s a breakpoint on that line:
debug> list()
> 1 (function (exports, require, module, __filename, __dirname) { const puppeteer = require('puppeteer');
2 const url = 'https://myaccount.rid.org/Public/Search/Member.aspx';
3
4 async function main() {
* 5 const browser = await puppeteer.launch({ headless: false, slowMo: 250 });
Now type c to continue execution until the breakpoint. Once you hit the breakpoint on line 5, type n
to execute one line at a time until you get to the console.log() statement on line 9:
debug> c
break in rid_scraper.js:5
3
4 async function main() {
> 5 const browser = await puppeteer.launch({ headless: false, slowMo: 250 });
6 const page = await browser.newPage();
7
debug> n
break in rid_scraper.js:6
4 async function main() {
* 5 const browser = await puppeteer.launch({ headless: false, slowMo: 250 });
> 6 const page = await browser.newPage();
7
8 await page.goto(url);
debug> n
break in rid_scraper.js:8
6 const page = await browser.newPage();
7
> 8 await page.goto(url);
9 console.log(await page.title());
10 await browser.close();
debug> n
break in rid_scraper.js:9
7
8 await page.goto(url);
> 9 console.log(await page.title());
10 await browser.close();
11 }
Type n again to execute the console.log() statement on line 9. You’ll see the page title “Find an RID Member” appear prefixed
with the < symbol:
debug> n
break in rid_scraper.js:9
7
8 await page.goto(url);
> 9 console.log(await page.title());
10 await browser.close();
11 }
debug> n
< Find an RID Member
break in rid_scraper.js:10
8 await page.goto(url);
9 console.log(await page.title());
>10 await browser.close();
11 }
12
Finally, type in c to continue execution until the end of the program. Type in <CTRL-D> to exit the debugger:
debug> c
< Waiting for the debugger to disconnect...
debug> ^D
Now that you’ve seen the basics of how to use the debugger, let’s start adding the core functionality to our scraper.
Implementation
As I mentioned earlier, the form we’re scraping requires us to fill
out at least two fields. In our code those will be the Freelance Status and State fields. Inspect the Freelance Status
dropdown in Chrome developer tools to see its id value:
<select id="FormContentPlaceHolder_Panel_freelanceDropDownList">
<option selected="selected" value=""></option>
<option value="1">Yes</option>
<option value="0">No</option>
Now that we have the id, we can select the Yes option for the Freelance Status using Puppeteer’s
page.select method:
await page.select('#FormContentPlaceHolder_Panel_freelanceDropDownList', '1');
To retrieve all of the states, we’ll first create a generic function that returns the options under a select element. We’ll use
Puppeteer’s page.evaluate
function to locate the <select> element that matches selector and return all of the available options for that element as an array
of text,value pairs.
async function getSelectOptions(page, selector) {
const options = await page.evaluate(optionSelector => {
return Array.from(document.querySelectorAll(optionSelector))
.filter(o => o.value)
.map(o => {
return {
name: o.text,
value: o.value
};
});
}, selector);
return options;
}
Next, inspect the State dropdown menu to see its id:
<select id="FormContentPlaceHolder_Panel_stateDropDownList">
<option selected="selected" value=""></option>
<option value="d8fcccc5-cf2f-e511-80c5-00155d631510">Alabama</option>
<option value="dafcccc5-cf2f-e511-80c5-00155d631510">Alaska</option>
<option value="befcccc5-cf2f-e511-80c5-00155d631510">Alberta</option>
...
</select>
Now we can easily retrieve the state option values using:
async function getStates(page) {
return await getSelectOptions(page,
'select#FormContentPlaceHolder_Panel_stateDropDownList > option'
);
}
Now let’s go back to main() and update it to iterate through the list of states and submit
a search for each state with the the Freelance Status field to Yes. We’ll also add in code
to wait for the results to show up in the table.
async function main() {
const browser = await puppeteer.launch({ headless: false, slowMo: 250 });
const page = await browser.newPage();
await page.goto(url);
let states = await getStates(page);
for (const [ i, state ] of states.entries()) {
console.log(`[${i+1}/${states.length}] Scraping data for ${state.name}`);
await page.select('#FormContentPlaceHolder_Panel_stateDropDownList', state.value);
await page.select('#FormContentPlaceHolder_Panel_freelanceDropDownList', '1');
await page.click('#FormContentPlaceHolder_Panel_searchButtonStrip_searchButton');
await page.waitForSelector('#FormContentPlaceHolder_Panel_resultsGrid');
break;
}
await browser.close();
}
main();
First we use page.select to select the State and Freelance Status options. Then we call page.click to click on the Find Members search button. Once we’ve submitted the search we wait until the results table appears using waitForSelector.
Now run node inspect rid_scraper.js so that you can step through the code a line at a time and see the State and
Freelance Status fields get updated in the browser being controlled by the script. You can examine the values of the
variables as you’re stepping through the code via the repl command:
debug> repl
Press Ctrl + C to leave debug repl
> i
0
> states.length
73
> states[0]
{ name: 'Alabama',
value: 'd8fcccc5-cf2f-e511-80c5-00155d631510' }
> ^C
Now that we’ve written the code to submit the form, let’s create a scrapeMemberTable function to scrape the results:
async function scrapeMemberTable(page) {
const data = await page.evaluate(() => {
const ths = Array.from(document.querySelectorAll('table th'));
const trs = Array.from(document.querySelectorAll('table tr.RowStyle'));
const headers = ths.map(th => th.innerText);
let results = [];
console.log(`${trs.length} rows in member table!`);
trs.forEach(tr => {
let r = {};
let tds = Array.from(tr.querySelectorAll('td')).map(td => td.innerText);
headers.forEach((k,i) => r[k] = tds[i]);
results.push(r);
});
return results;
});
console.log(`Got ${data.length} records`);
return data;
}
The scrapeMemberTable function collects all of the data from each table row using the table headers as keys
to create a dictionary of results.
At this point, we’re able to scrape the first page of results, but we need to be able to iterate through all of the pages. If you look at the pager below the results table, you’ll see that subsequent pages show up as links but the current page does not:


Inspect the pager to see the pattern for the next page links.

And the pattern for the current page.

We’ll find the next page link by searching for the pattern Page$<pagenum>. Once we find and click on the next page’s link,
we’ll need to wait for that page to load and become the current page before collecting the results. We can do that by
waiting for the page number we click on to appear within a <span>:
/*------------------------------------------------------------------------------
* Look for link for pageno in pager. So if pageno was 6 we'd look for 'Page$6'
* in href:
*
* <a href="javascript:__doPostBack('ctl00$FormContentPlaceHolder$Panel$resultsGrid','Page$6')">...</a>
*
* After the next page link gets clicked and the new page is loaded the pager
* will show the current page within a span (not as a link). So we wait until
* pageno appears within a span to indicate that the next page has finished
* loading.
*/
async function gotoNextPage(page, pageno) {
let noMorePages = true;
let nextPageXp = `//tr[@class='PagerStyle']/td/table/tbody/tr/td/a[contains(@href,'Page$${pageno}')]`;
let currPageXp = `//tr[@class='PagerStyle']/td/table/tbody/tr/td/span[text()='${pageno}']`;
let nextPage;
nextPage = await page.$x(nextPageXp)
if (nextPage.length > 0) {
console.log(`Going to page ${pageno}`);
await nextPage[0].click();
await page.waitForXPath(currPageXp);
noMorePages = false;
}
return noMorePages;
}
Here we use Puppeteer’s page.$x
method to search for the next page link. After clicking the link, we call page.waitForXPath to wait for the page number we just clicked on to appear within a <span>. Once we’ve
reached the last page gotoNextPage will leave noMorePages set to true, to indicate to the caller that there’s
no more pages left to click through.
Now that we have a way to go to the next page, we can create a scrapeAllPages function to iterate through
all of pages, collecting the results on each page as we go.
async function scrapeAllPages(page) {
let results = [];
let pageno = 2;
while (true) {
console.log(`Scraping page ${pageno - 1}`);
results = results.concat(
await scrapeMemberTable(page)
);
const noMorePages = await gotoNextPage(page, pageno++)
if (noMorePages) {
break;
}
}
/*
* The pager won't reset back to page 1 on its own so we have to explicitly
* click on the page 1 link
*/
await gotoFirstPage(page);
return results;
}
At the end of the scrapeAllPages is a call to gotoFirstPage. This function takes us back to the first page of results.
Why is this necessary? Because once you get to the last page and start a new search the pager does not reset.
In other words, if you’re on the last page of results for Alabama and then you do a search for Alaska, the last page of results for Alaska comes up instead of the first page.
In order to handle this we explicitly click the page 1 link before starting a new search:
/*------------------------------------------------------------------------------
* Go back to the first page of results in order to reset the pager. Once the
* first page link is clicked and becomes the current page the page 1 link will
* appear inside of <span>1</span>. So we can determine once page 1 has finished
* loading by waiting until page 1 appears inside of this span.
*
* Note that there might not be a page 1 link because there was only one page of
* results. In that case the page will still show up as <span>1</span> element.
*/
async function gotoFirstPage(page) {
let firstPageLinkXp = `//tr[@class='PagerStyle']/td/table/tbody/tr/td/a[contains(@href,'Page$1')]`;
let firstPageCurrXp = `//tr[@class='PagerStyle']/td/table/tbody/tr/td/span[text()='1']`;
let firstPage;
firstPage = await page.$x(firstPageLinkXp);
if (firstPage.length > 0) {
await firstPage[0].click();
}
await page.waitForXPath(firstPageCurrXp);
}
Now we have code that can iterate through all of the pages of results. However, there’s an optimization we can make here. On the right size of the pager is a dropdown where we can select the number of results that show up on each page. By setting this dropdown to its maximum value (50) we can reduce the total number of pages (and requests to the server) that our scraper will have have to click through.
When you select one of the page size options in this dropdown it will dynamically update the results table. That means we need to be able to determine when that update has completed.
If you inspect the page size <select> in Chrome Developer Tools you’ll see that it does not have an id
attribute. We’ll have to locate it by searching for its name attribute instead:
<select name="ctl00$FormContentPlaceHolder$Panel$resultsGrid$ctl11$ctl06"
onchange="javascript:setTimeout('__doPostBack(\'ctl00$FormContentPlaceHolder$Panel$resultsGrid$ctl11$ctl06\',\'\')', 0)">
<option value="5">5</option>
<option selected="selected" value="10">10</option>
<option value="20">20</option>
<option value="50">50</option>
</select>
But there’s a catch: the value for the name attribute is not consistant. In other words, we can’t just hardcode
the name value in our code because it changes each time we perform a new search.
Taking all of this into account, we create a setMaxPageSize() function that locates the name value using a
regex to search the page source HTML which we access via page.content.
Then we select the maximum page size from the dropdown and wait for the old results table to be updated.
How do we determine when the results table has updated? By waiting until the current table detaches from the DOM. We’ll use that as the signal that the new results table has been loaded into place:
async function setMaxPageSize(page) {
let html = await page.content();
let pageSizeNameRe = new RegExp(
'ctl00\\$FormContentPlaceHolder\\$Panel\\$resultsGrid\\$ctl\\d+\\$ctl\\d+'
);
let match = pageSizeNameRe.exec(html);
if (match.length <= 0) {
return;
}
let pageSizeName = match[0];
let resultsTable = await page.$('#FormContentPlaceHolder_Panel_resultsGrid');
await page.select(`select[name="${pageSizeName}"]`, '50');
/*
* Selecting the page size triggers an ajax request for the new table results.
* We need to wait until that new table data gets loaded before trying to scrape.
* So we wait until the old member table gets detached from the DOM as the signal
* that the new table has been loaded
*/
await waitUntilStale(page, resultsTable);
}
The waitUntilStale function waits for an element to become detached from the DOM by passing
in a predicate function to Puppeteer’s waitForFunction:
/*
* Wait until elem becomes detached from DOM
*/
async function waitUntilStale(page, elem) {
await page.waitForFunction(
e => !e.ownerDocument.contains(e),
{ polling: 'raf' }, elem
);
}
At this point, we have enough functionality to complete our scraper:
async function main() {
const browser = await puppeteer.launch({ slowMo: 250 });
const page = await browser.newPage();
page.on('console', msg => console.log('PAGE LOG:', msg.text()));
await page.goto(url);
let states = await getStates(page);
for (const [ i, state ] of states.entries()) {
console.log(`[${i+1}/${states.length}] Scraping data for ${state.name}`);
await page.select('#FormContentPlaceHolder_Panel_stateDropDownList', state.value);
await page.select('#FormContentPlaceHolder_Panel_freelanceDropDownList', '1');
/*
* The first time we run a search we can wait for the table to appear to determine
* once the search has loaded the results. However, with subsequent searches the
* table already exists and what we need to determine is when the table contents have
* been updated. To do that we fetch a reference to the table here and then wait for
* it to become stale (detached) as an indication that the new table data has loaded.
*/
let resultsTable = await page.$('table#FormContentPlaceHolder_Panel_resultsGrid');
await page.click('#FormContentPlaceHolder_Panel_searchButtonStrip_searchButton');
if (resultsTable) {
await waitUntilStale(page, resultsTable);
} else {
await page.waitForSelector('#FormContentPlaceHolder_Panel_resultsGrid');
}
/*
* The page size is retained after the first time its set, so we only
* need to call this once
*/
if (i === 0) {
await setMaxPageSize(page);
}
let data = await scrapeAllPages(page);
console.log(`Got ${data.length} records for state ${state.name}`);
console.log(JSON.stringify(data, null, 2));
/* Only grab the first three states for demo purposes */
if (i >= 2) {
break;
}
}
await page.close();
await browser.close();
}
main();
The browser is launched with the slowMo option set to 250ms. This makes it easier to watch the script progress and also ensures that we don’t hit the site too quickly. I’ve also limited the script to the first three states.
As was done in the setMaxPageSize() function, we wait for the results table to become stale on subsequent searches to determine when new results are loaded
as we iterate through each state.
Conclusion
At this point, we’ve covered most of the basic techniques you’ll use when developing a scraper:
- Loading a page and waiting for specific elements to appear
- Scraping/collecting the results from a response page
- Handling pagination
- Detecting when an element has been updated dynamically by waiting for that element to become stale
- Stepping through your code with a debugger
The code developed in this article is available as a gist at:
https://gist.github.com/thayton/3185339aa43b6bb49ddafc611102e90a