Using Selenium to Scrape ASP.NET Pages with AJAX Pagination
14 May 2015In my last post I went over the nitty-gritty details of how to scrape an ASP.NET AJAX page using Python mechanize. Since mechanize can’t process Javascript, we had to understand the underlying data formats used when sending form submissions, parsing the server’s response, and how pagination is handled. In this post, I’ll show how much easier it is to scrape the exact same site when we use Selenium to drive PhantomJS.
Background
The site I use in this post is the same as the one I used in my last post: the search form provided by The American Institute of Architects for finding architecture firms in the US.
http://architectfinder.aia.org/frmSearch.aspx
Once again, I’ll show to scrape the names and links of the firms listed for all of the states in the form.
First let’s set up our environment:
$ mkdir scraper && cd scraper
$ brew install phantomjs
$ virtualenv venv
$ source venv/bin/activate
$ pip install selenium
$ pip install beautifulsoup4
Here’s the class definition and skeleton code we’ll start out with. We’re going to add a scrape()
method that will submit the form for each item in the State select dropdown and then print out
the results.
#!/usr/bin/env python
"""
Python script for scraping the results from http://architectfinder.aia.org/frmSearch.aspx
"""
import re
import string
import urlparse
from selenium import webdriver
from selenium.webdriver.support.ui import Select
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import NoSuchElementException
from bs4 import BeautifulSoup
class ArchitectFinderScraper(object):
def __init__(self):
self.url = "http://architectfinder.aia.org/frmSearch.aspx"
self.driver = webdriver.PhantomJS()
self.driver.set_window_size(1120, 550)
if __name__ == '__main__':
scraper = ArchitectFinderScraper()
scraper.scrape()
Submitting the Form
Let’s get started. Click on the Architect Finder link:
http://architectfinder.aia.org/frmSearch.aspx
You’ll be presented with a modal for their Terms of Service.
You’ll need to click on the Ok button to continue on to the main site. Before you do that
though, inspect the Ok button in Developer Tools and you’ll see that it has the following
id attribute: ctl00_ContentPlaceHolder1_btnAccept. We’ll use that id when accepting the
ToS in our script.
After you accept the ToS agreement, you’ll be presented with the following form.
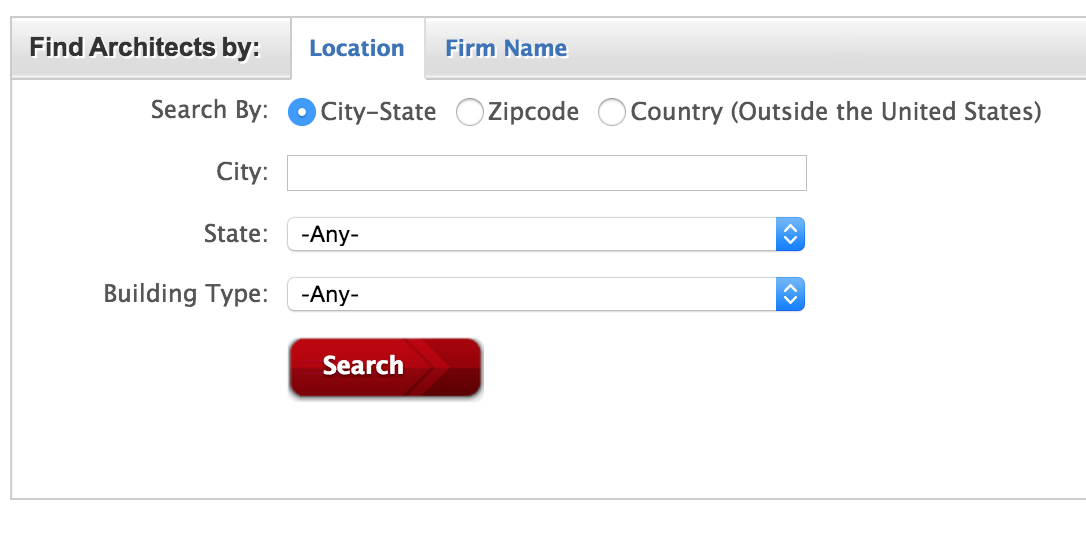
Click on the state selector and you’ll get a dropdown menu like the following:

If you look at the HTML associated with this dropdown, you’ll see that its id attribute is
set to ctl00_ContentPlaceHolder1_drpState:
<select name="ctl00$ContentPlaceHolder1$drpState" id="ctl00_ContentPlaceHolder1_drpState"
Next, select ‘Alaska’ from the dropdown and then click the Search button. A loader gif will appear while the results are being retrieved.

Inspect this gif in Developer Tools and you’ll find it in the following div:
<div id="ctl00_ContentPlaceHolder1_uprogressSearchResults" style="display: none;">
<div style="width: 100%; text-align: center">
<img alt="Loading.... Please wait" src="images/loading.gif">
</div>
</div>
The div’s style attribute gets set to display: none; once the results have finished loading.
We’ll use this fact to detect when the results are ready to be parsed in our script.
Let’s add a scrape() method to our class that does everything we’ve gone over so far.
def scrape(self):
self.driver.get(self.url)
# Accept ToS
try:
self.driver.find_element_by_id('ctl00_ContentPlaceHolder1_btnAccept').click()
except NoSuchElementException:
pass
# Select state selection dropdown
select = Select(self.driver.find_element_by_id('ctl00_ContentPlaceHolder1_drpState'))
option_indexes = range(1, len(select.options))
# Iterate through each state
for index in option_indexes:
select.select_by_index(index)
self.driver.find_element_by_id('ctl00_ContentPlaceHolder1_btnSearch').click()
# Wait for results to finish loading
wait = WebDriverWait(self.driver, 10)
wait.until(lambda driver: driver.find_element_by_id('ctl00_ContentPlaceHolder1_uprogressSearchResults').is_displayed() == False)
We iterate through each option in the state selection dropdown, submitting the form for each possible state value. After the form has been submitted, we must wait for the results to load. To do this, we use WebDriverWait to locate the div containing the loading gif and wait until that div is no longer being displayed.
# Wait for results to finish loading
wait = WebDriverWait(self.driver, 10)
wait.until(lambda driver: driver.find_element_by_id('ctl00_ContentPlaceHolder1_uprogressSearchResults').is_displayed() == False)
Extracting the Results
Now let’s move on to extracting the results. Our scrape() method is continued below.
def scrape(self):
...
# Iterate through each state
for index in option_indexes:
...
pageno = 2
while True:
s = BeautifulSoup(self.driver.page_source)
r1 = re.compile(r'^frmFirmDetails\.aspx\?FirmID=([A-Z0-9-]+)$')
r2 = re.compile(r'hpFirmName$')
x = {'href': r1, 'id': r2}
for a in s.findAll('a', attrs=x):
print 'firm name: ', a.text
print 'firm url: ', urlparse.urljoin(self.driver.current_url, a['href'])
print
After the results have finished loading, we feed the rendered page into BeautifulSoup. Then we extract the name and link for each architecture firm in the results. As I went over in my last post, each link has the following format:
<a id="ctl00_ContentPlaceHolder1_grdSearchResult_ctl03_hpFirmName"
href="frmFirmDetails.aspx?FirmID=F12ED5B3-88A1-49EC-96BC-ACFAA90C68F1">
Kumin Associates, Inc.
</a>
We find the links by matching on the href and id attributes. The href of these links is
matched using the regex
^frmFirmDetails\.aspx\?FirmID=([A-Z0-9-]+)$
and the id attribute can be matched using the regex hpFirmName$.
Pagination
Finally, let’s examine how to handle pagination. Below is a screenshot of the pager that shows up at the bottom of the results.

In order to get all of the results, we need to click on each page number link, starting with page 2. Same as before, we also need a way of determining when the results have finished loading after clicking a page number link.
Note that in the screenshot above the currently selected page (2) has its background color set differently than the other pages. If we look at the style attribute for the selected page we can see that the selected page has its background color set while all of the other non-selected pages do not.
<a style="display:inline-block;width:20px;">1</a>
<a style="display:inline-block;background-color:#E2E2E2;width:20px;">2</a>
We’ll use this fact to determine once the next page of results has finished loading. Here’s the
rest of the scrape() method that handles pagination.
def scrape(self):
...
# Iterate through each state
for index in option_indexes:
...
pageno = 2
while True:
...
# Pagination
try:
next_page_elem = self.driver.find_element_by_xpath("//a[text()='%d']" % pageno)
except NoSuchElementException:
break # no more pages
next_page_elem.click()
def next_page(driver):
'''
Wait until the next page background color changes indicating
that it is now the currently selected page
'''
style = driver.find_element_by_xpath("//a[text()='%d']" % pageno).get_attribute('style')
return 'background-color' in style
wait = WebDriverWait(self.driver, 10)
wait.until(next_page)
pageno += 1
self.driver.quit()
First we find the next page number link using the xpath expression "//a[text()='%d']" % pageno.
If no such link is found then we must already be on the last page. Otherwise, we click the link
and wait for the next page results to finish loading.
To wait for the results to load we once again use WebDriverWait, this time with the following
predicate function:
def next_page(driver):
'''
Wait until the next page background color changes indicating
that it is now the currently selected page
'''
style = driver.find_element_by_xpath("//a[text()='%d']" % pageno).get_attribute('style')
return 'background-color' in style
If you put a print statement in the next_page function, you’ll see it getting called multiple
times until it returns True.
Conclusion
That’s it! If you compare this scraper to the one using mechanize in my previous post, you’ll see how much shorter and simpler it is. You can view the source for both scrapers on github at the following link:
https://github.com/thayton/architectfinder
Shameless Plug
Have a scraping project you’d like done? I’m available for hire. Contact me for a free quote.